
Description of insert-on-duplicate statement in MySQL
1. insert-on-duplicate statement syntax
Note: ON DUPLICATE KEY UPDATE is a MySQL specific syntax, not a standard SQL syntax!
INSERT INTO … ON DUPLICATE KEY UPDATE is a syntax in MySQL for inserting data and handling duplicate key conflicts.
This syntax applies to insert, if the insert data will cause a unique index (including the primary key index) conflict, that is, the unique value is repeated, the insert operation will not be performed, and the subsequent update operation will be performed.
The basic syntax is:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...) ON DUPLICATE KEY UPDATE column1 = value1, column2 = value2, ... ; INSERT INTO table_name (column1, column2,...) INSERT into table_name (column1, column2,...) VALUES (value1, value2, ...) ON DUPLICATE KEY UPDATE column1 = VALUES(column1), column2 = VALUES(column2), ... ;
Instructions:
- table_name is the name of the table into which data is to be inserted.
- (column1, column2, …) Is a list of column names to insert.
- (value1, value2, …) Is a list of values for the corresponding column to be inserted.
- The ON DUPLICATE KEY UPDATE clause specifies the update operation that needs to be performed in case of a conflict.
- column1 = value1, column2 = value2, … Is the column to update and the corresponding new value.
- column1 = VALUES(column1), column2 = VALUES(column2), … Is the column to be updated and the corresponding new value (the value in the insert section).
insert-on-duplicate statement processing logic:
The statement determines whether a record is duplicated based on a unique index. When the insert operation is performed, if the unique keys do not conflict (no record exists in the table), the insert operation is performed. If a unique key conflict is encountered (there are records in the table), an update operation is performed to update the columns in the conflict row with the given new value.
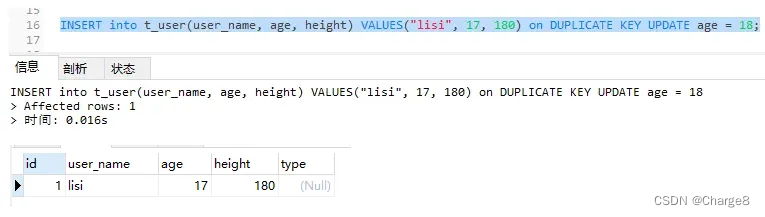
- If no record exists, insert it, and the number of rows affected is 1.
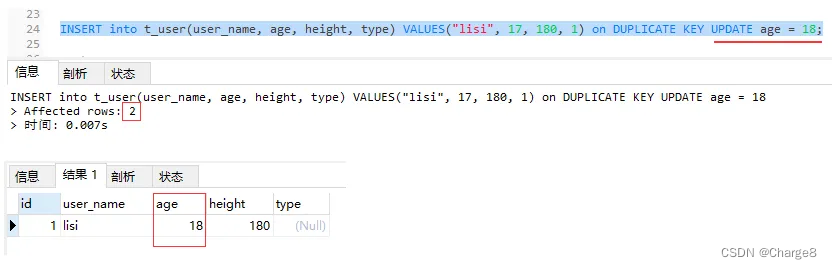
- If a record exists and the field can be updated, the number of rows affected is 2;
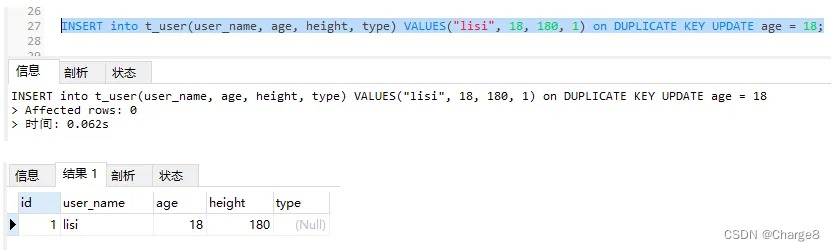
- If a record exists and the updated value is the same as the original value, the number of rows affected is 0.
Note: If the table has multiple unique indexes, only the first column unique index with the corresponding value in the database is checked by duplicate.
2. Example table operation
t_user table structure: The table has a primary key id and a unique index idx_name.
CREATE TABLE 't_user' (' id 'int(11) NOT NULL AUTO_INCREMENT COMMENT' primary key ID', 'user_name' varchar(30) NOT NULL COMMENT 'user name ',' age 'int NOT NULL DEFAULT '0' COMMENT' age ', 'height' int DEFAULT '0' COMMENT 'Height cm',' type 'int(1) DEFAULT NULL COMMENT' type ', PRIMARY KEY (' id '), UNIQUE KEY `idx_name` (`user_name`) USING BTREE, KEY 'idx_type' (' type ') USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=' user table ';
1, there is no record, insert the case
INSERT into t_user(user_name, age, height) VALUES("lisi", 17, 180) on DUPLICATE KEY UPDATE age = 18;
2. Records exist and fields can be updated
INSERT into t_user(user_name, age, height) VALUES("lisi", 17, 180) on DUPLICATE KEY UPDATE age = 18;
3. Records exist and fields cannot be updated
INSERT into t_user(user_name, age, height, type) VALUES("lisi", 18, 180, 1) on DUPLICATE KEY UPDATE age = 18;
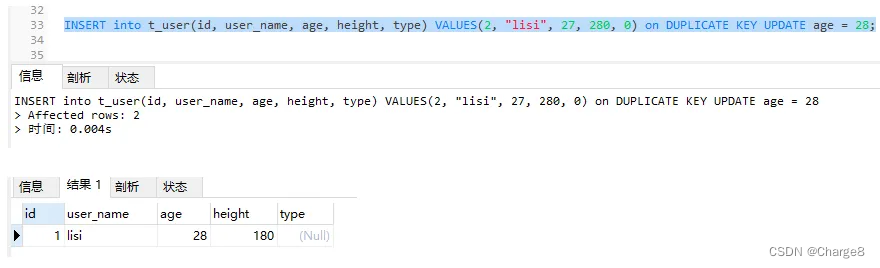
4. When there are multiple unique indexes
If the table has multiple unique indexes, only the first column with the corresponding value in the database is checked by duplicate.
1) The record with id = 2 in the database does not exist and the record with user_name="lisi" does, so the duplicate judgment is made according to the second unique index user_name: update operation is performed.
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisi", 27, 280, 0) on DUPLICATE KEY UPDATE age = 28;
2) The record with id = 2 and user_name="lisisi" does not exist in the database, so there is no duplicate key conflict: Perform insert operation.
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 27, 280, 0) on DUPLICATE KEY UPDATE age = 28;
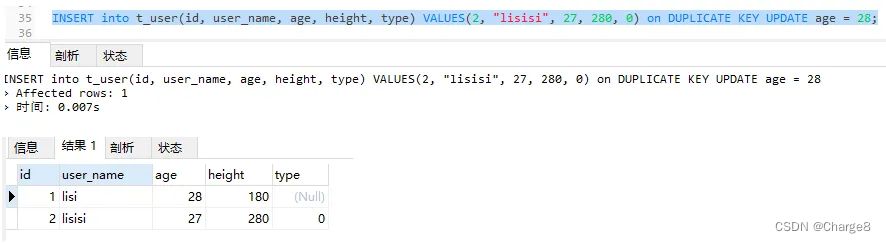
3) There is a record with id = 2 and user_name="lisisi" in the database, so the duplicate judgment is made based on the id of the first unique index: the update operation is performed.
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 37, 380, 1) on DUPLICATE KEY UPDATE age = 38;
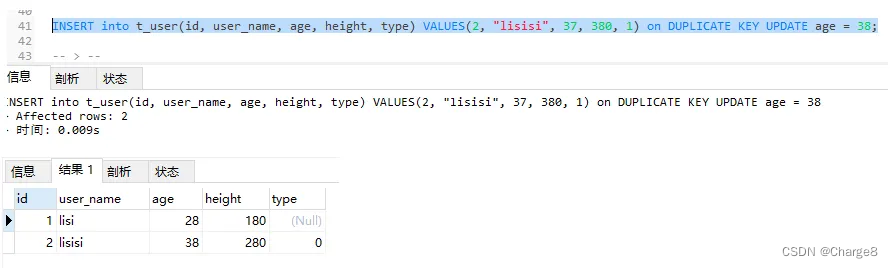
4) Record with id = 2 exists in the database and user_name="lisisi2" does not. Therefore, the duplicate judgment is made based on the id of the first unique index: update operation is performed.
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi2", 47, 480, 0) on DUPLICATE KEY UPDATE age = 48;
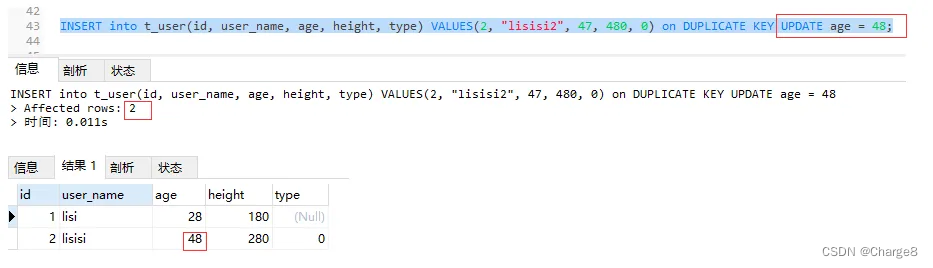
5. VALUES(col_name) are used
The normal Update clause can obtain the VALUES of the insert section using VALUES(col_name). It is also the most used method in the project.
Note: The VALUES() function is used only in INSERT... The UPDATE statement makes sense, other times it returns NULL.
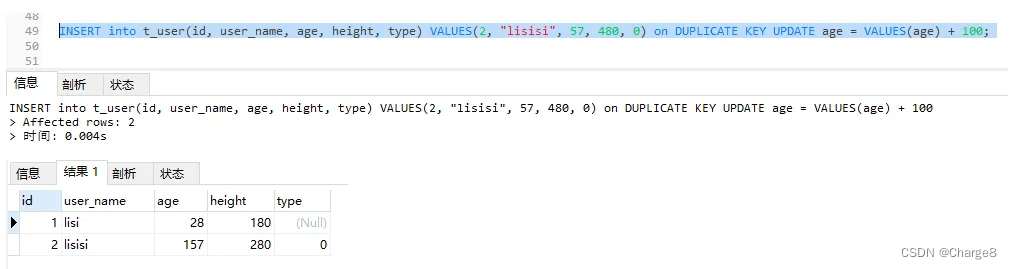
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 57, 480, 0) on DUPLICATE KEY UPDATE age = VALUES(age) + 100;
6, batch operation
The data in the table before batch operation is as follows:
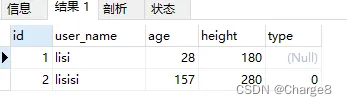
The batch statement is as follows:
INSERT INTO t_user(user_name, age, height, type)
VALUES
("lisi", 71, 701, 0),
("lisisi", 72, 280, 1),
("zhangsan", 73, 703, 0),
("wangwu", 74, 704, null),
("laoliu", 75, null, null)
ON DUPLICATE KEY UPDATE
user_name = VALUES(user_name),
age = VALUES(age),
height = VALUES(height),
type = VALUES(type);
After the batch statement is executed, the data in the table is as follows:

Reference article:
- The official document: https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
Sum up
This article about the insert-on-duplicate statement in MySQL is introduced to this, more related to MySQL insert-on-duplicate statement content please search the previous articles of Script House or continue to browse the following related articles hope that you will support Script House in the future!
Related article
-

Periodically back up mysql and periodically cut the nginx access log
Regular backup mysql, regular cutting nginx access log method, need friends can refer to the next.2011-09-09 -

MySQL learning index and optimization
This article mainly introduces MySQL index and optimization, index is a data structure to help MySQL query efficiently. Like a book's catalog, it can speed up the query, and small partners who want to know more can read this article in detail2023-03-03 -

This section describes how to configure the mysql no-installation version
This article mainly tells you about the actual configuration method of the MySQL free installation version, as well as the relevant download site also has a detailed introduction, I hope you will have something.2010-08-08 -

Examples of stored functions and triggers in MySQL development
This article mainly introduces in detail the creation of the MySQL storage function and the setting of the trigger, the example code in the article explains in detail, has a certain learning value, you can refer to it2023-01-01 -

Windows MySQL8.0.21 installation tutorial (illustrated details)
This article mainly introduces the Windows system MySQL8.0.21 installation tutorial, this article through the form of illustrations to give you a very detailed introduction, for everyone's study or work has a certain reference value, the need of friends can refer to2020-08-08 -

How do SQL results get the latest time for a field
In daily project development, often encounter to obtain the same attribute of the same record, how to obtain the record time of the latest one, the following article mainly introduces to you about the SQL results how to take the latest time according to a field to heavy relevant information, need friends can refer to2023-06-06 -

mysql limit query step pit actual records
In MySQL, we often use order by to sort, use limit to paginate, the following article mainly introduces the relevant information about the mysql limit query treading pit, the article introduces the example code is very detailed, the need of friends can refer to the next2023-03-03 -

MySQL performance optimization of the best 20 experiences to share
Today, database operations are increasingly becoming a performance bottleneck for the entire application, especially for Web applications. As for database performance, this is not only something that DBAs need to worry about, but it is something that we programmers need to pay attention to.2010-07-07 -

Usage and description of max_allowed_packet for Mysql performance tuning
This article mainly introduces the use and description of max_allowed_packet for Mysql performance tuning, which has a good reference value and hopes to help you. If there are mistakes or incomplete areas, please feel free to comment2022-11-11 -

Details of MySQL table column number and row size limits
MySQL has some restrictions on the number of columns and row size of the table, this article will explain these restrictions in detail, the article through the code example explained in detail, to everyone's study or work has certain help, need friends can refer to2024-04-04
Latest comments